NLTK简介
NLTK(Natural Language Toolkit)是一个用Python写的自然语言处理工具箱,源自宾州大学的Steven Bird 和 Edward Loper。
NLTK的功能
NLTK包含的功能:
NLTK安装
Ubuntu下使用pip安装1
sudo pip3.6 install nltk
安装完后,需要下载语料库,由于语料库比较大,使用nltk.download()方法下载时太慢,推荐参考这里,语料库,密码:u3kn
探索数据
- 数据搜索路径
1
nltk.data.find('/')
会列出当前数据搜索路径
- 语料库包含哪些数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 导入 gutenberg 集
from nltk.corpus import gutenberg
# 都有些什么语料在这个集合里?
print gutenberg.fileids()
# 导入 FreqDist 类
from nltk import FreqDist
# 频率分布实例化
fd = FreqDist()
# 统计文本中的词例
for word in gutenberg.words('austen-persuasion.txt'):
fd.inc(word)
print fd.N() # total number of samples
#98171
print fd.B() # number of bins or unique samples
#6132
# 得到前 10 个按频率排序后的词
for word in fd.keys()[:10]:
print word, fd[word]
4个自然语言处理基本任务
自然语言处理包含4个基本任务,分别是
- 分词
- 词性标注
- 命名实体识别
- 句法分析
分词
其中分词可以分为两部分来进行,分别是分句(将文章切分成句子列表)、分词(将句子切分成词列表)
代码如下:
1 | import nltk |
词性标注
nltk.pos_tag(tokens)
1 | tagged = nltk.pos_tag(tokens) |
命名实体识别
nltk.ne_chunk(tags)
1 | entities = nltk.chunk.ne_chunk(tagged) |
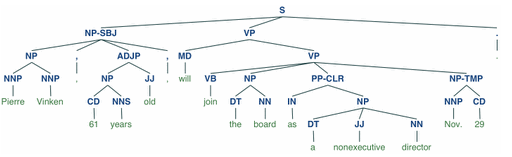
句法树
nltk没有好的parser,推荐使用stanfordparser
但是nltk有很好的树类,该类用list实现
可以利用stanfordparser的输出构建一棵python的句法树
1 | from nltk.corpus import treebank |