要把语言交给机器学习中的算法去处理,通常首先需要将语言数学化,这种数学化的方式统称为:表示
下面分别接讨论两个问题,词向量化与文档向量化
1.词向量化(word2vec)
2.文档向量化(text2vec)
为什么要介绍文档向量化,比如在使用LDA模型时,LDA将整个文档视为词袋模型(Bag of Word),这个词袋模型就是文档向量化的一种方式,词袋模型的思想是,首先得到文档中不重复的词的集合,记为voc(字典),其次,对于一个文档(doc or text),然后初始化一个与字典长度相同的向量,将其对应位置设置为这个文档中词的频数,如下图所示:
1.经过分词后的doc
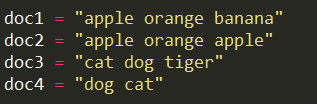
2.构建个不重复的词集voc

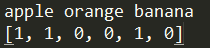
3.使用bow表示的doc1
代码如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46#1. 数据
doc1 = "apple orange banana"
doc2 = "apple orange apple"
doc3 = "cat dog tiger"
doc4 = "dog cat"
doc_set = [doc1,doc2,doc3,doc4]
#2. 分词
doc_tokenize = []
for doc in doc_set:
doc_tokenize.append(nltk.word_tokenize(doc))
print(doc_tokenize)
#3. 构建词集
def create_vocabulary(doc_tokenize):
vocabSet = set()
for doc in doc_tokenize:
vocabSet = vocabSet | set(doc)
return list(vocabSet)
voc = create_vocabulary(doc_tokenize)
voc = sorted(voc)
print(voc)
#4. 表示(文档向量)
def bow(vocabSet,inputset):
returnVec = [0 for t in range(len(vocabSet))]
for word in inputset:
if word in vocabSet:
returnVec[vocabSet.index(word)] += 1
return returnVec
bow1 = bow(voc,doc_tokenize[0])
print(doc1)
print(bow1)
'''
#5 表示(文档矩阵)
'''
doc_matrix = []
for doc in doc_tokenize:
doc_matrix.append(bow(voc,doc))
print(doc_matrix)
输出如下所示: