0.如何研究一个框架
研究一个大型软件(框架甚至是操作系统),无非是先使用,在研究其设计思想(原理),在研究设计思想的时候,无非就是横向和纵向。其中横向就是研究其模块划分或者架构architecture,纵向就是研究某一操作的工作流,比如hdfs操作中的文件下载过程。下面通过debug方式阅读hdfs源码,了解hdfs下载文件的过程。
1.先来一段hdfs下载文件的代码
在第4行打上断点,run as debug1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop:9000/");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream is = fs.open(new Path("/hello"));
FileOutputStream os = new FileOutputStream("d:/temp/");
IOUtils.copy(is, os);
}
2. RPC
在debug这段代码之前,首先要对hdfs文件下载的原理有一个大概的认识,这样有利于提取主线任务,不
至于掉到源代码的海洋中,迷失方向。
hdfs 下载文件时,是通过RPC机制调用远程方法实现的,具体来说,现在有一个client,需要下载文件
,那么,需要在client中先生成一个fs对象,如上代码所示,FileSystem是一个抽象类,最终获取到的是DFS
对象,在fs中需要生成服务端即namenode的代理对象,使用ClientProtocol(这个协议是双方的方法协议,
也就是客户端和远程要共同实现的一些方法),在拿到namenode的代理对象后,客户端就可以调用远程namenode的方法,去获取block元信息,在NameNode
上在通过拿到DataNode的代理对象,就可以调用DataNode上的方法,这样就可以完成下载文件过程。
3. 获取fs对象
获取fs对象的关键是给DFSClient成员变量赋值,在这些成员变量中最重要的是namenode的代理对象。
下面开始debug
首先在17行打上断点,跟踪进去
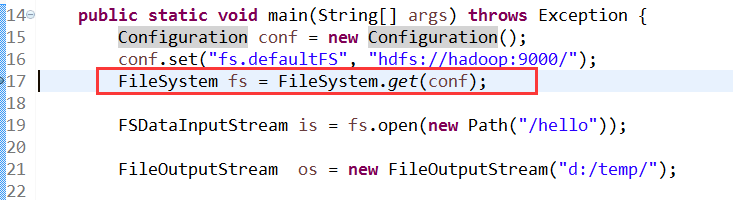
跟踪进入get

跟踪进入get(uri,conf)
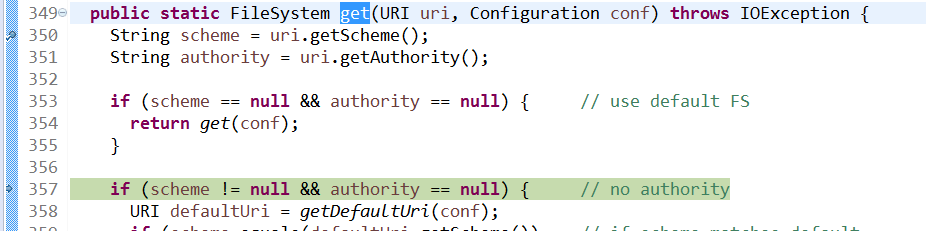
执行到该方法的最后一步

跟踪进入FileSystem$Cache.get(uri,conf)

跟踪进入FileSystem$Cache.getInternal(uri,conf,key)
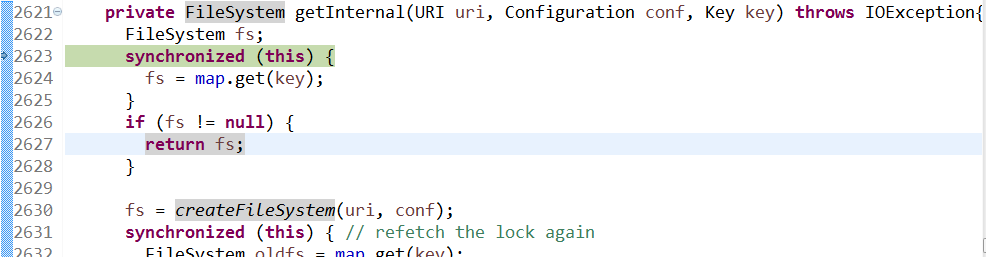
跟踪进入createFileSystem
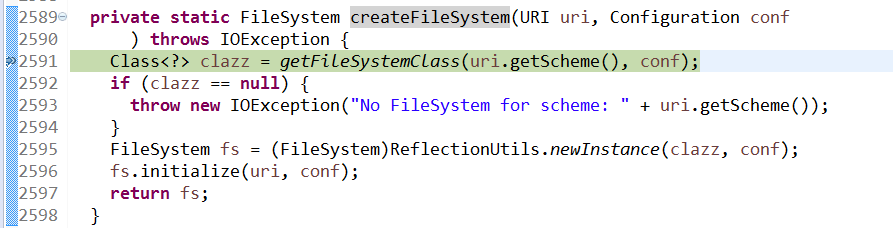
此时可以看到,clazz已经获取到DFS
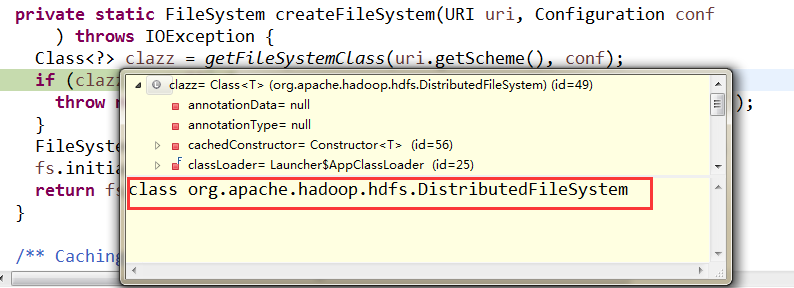
通过反射获取到一个DFS对象,此时DFS对象还是空的
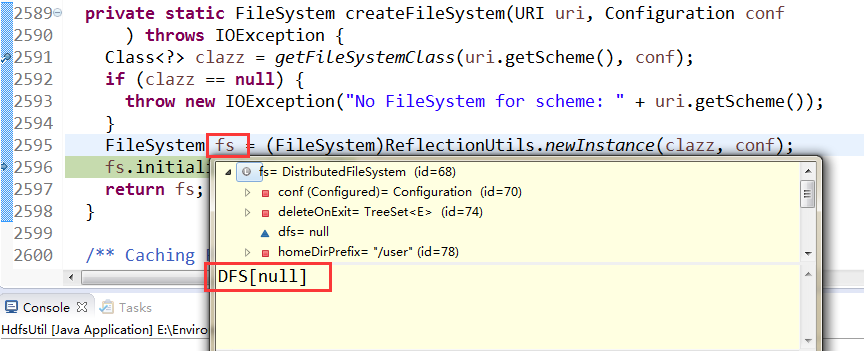
初始化DFS对象,给相应的field(成员变量)赋值,最后返回fs
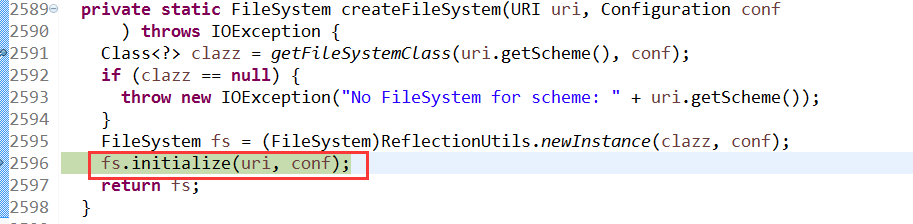
跟踪进入initialize,在这里创建了DFSClient
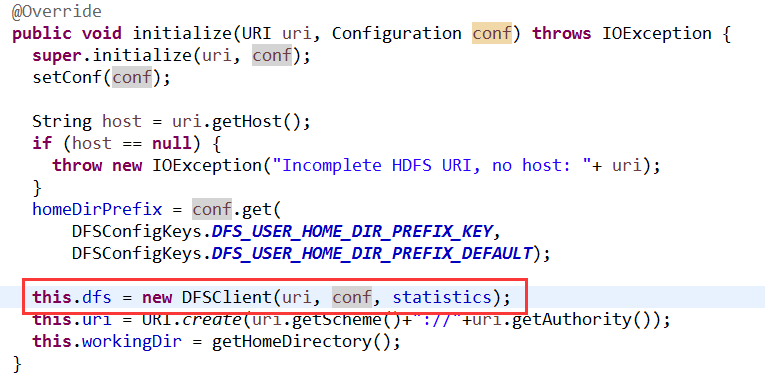
初始化DFSClient
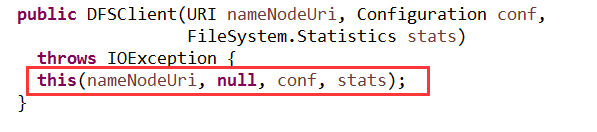
初始化DFSClient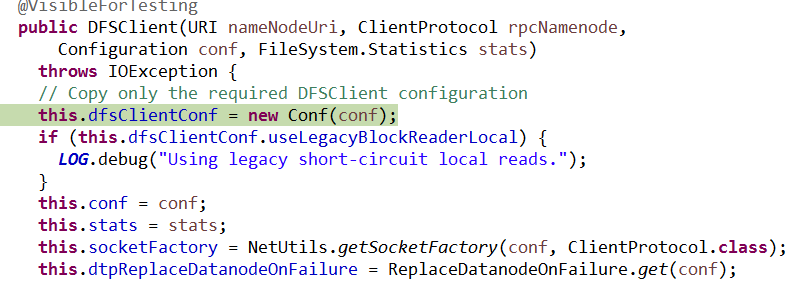
在DFSClient中,在这里创建proxyInfo

接着跟踪进入createProxy,这里创建NN的代理对象
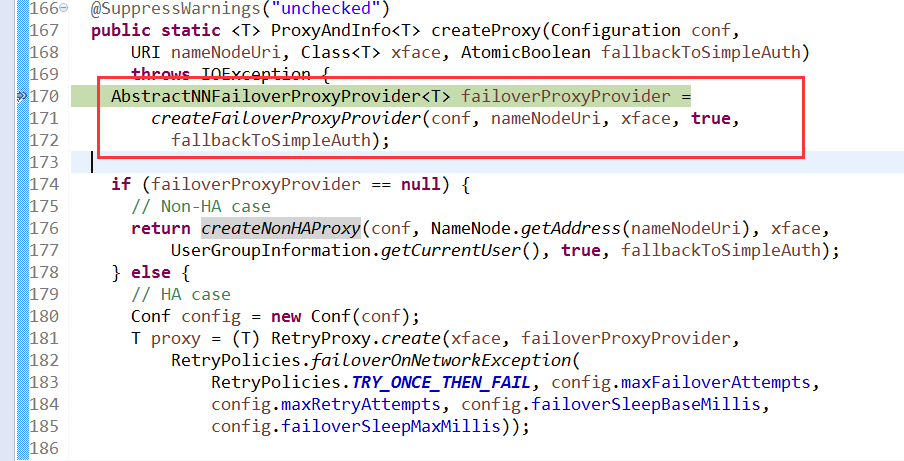
接着跟踪进入,createNonHAProxy创建非HA的NN代理
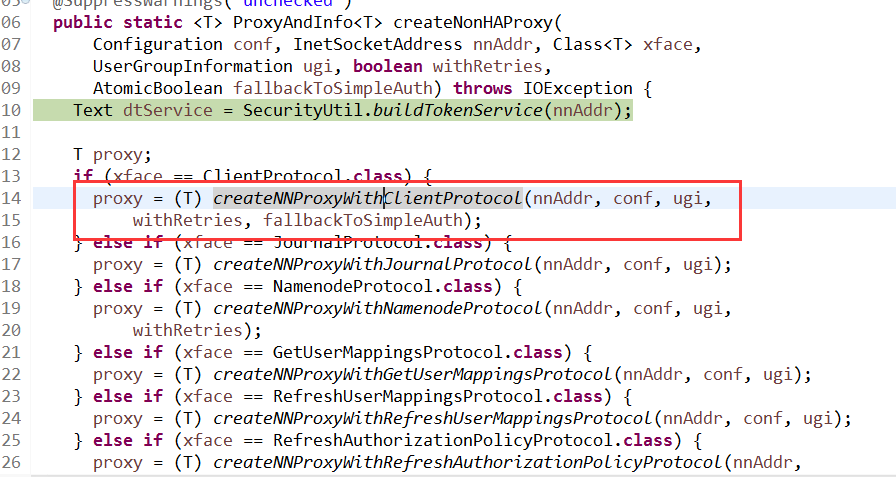
跟踪进入createNNProxyWithClientProtocol,获取版本号,获取proxy

返回proxy,返回的时候还封装了一下,为的是语言无关的序列化。hadoop中的序列化机制,使用一种描述性语言,得到语言无关的序列化

返回proxyAndInfo

最后贴上获取fs对象的调用方法栈
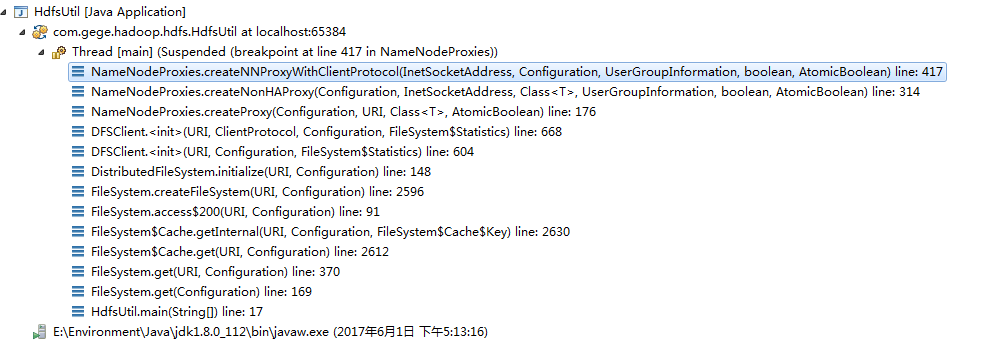
其实跟踪的时候,无非是三个操作,进入,操作,返回,其中进入和返回互为逆过程。
需要注意的是,ClientProtocol是客户端和远程要共同实现的一些方法,DFS持有一个namenode,也就是远程的name的proxy代理对象
总结一下上述过程,首先是在抽象类FileSystem中的通过conf的uri的schema获取到要创建的文件系统实例
对象,这里是DFS,在获取的过程中,首先获取到schema,在获取全路径类名,然后通过反射实例化一个空
的DFS对象,此前过程都是在FileSystem中完成的,initialize过程是在DFS中完成的,再通过initialize方
法给相应的成员变量赋值,DFS中有一个是重要的成员变量是DFSClient,因为这个成员变量包含了NN的代理
对象,在DFSClient,初始化DFSClient的时候,先声明NameNodeProxies.ProxyAndInfo
类型的proxyInfo变量,再通过NameNodeProxies.createProxy(conf,nameNodeUri,ClientProtocol.class,
nnFallbackToSimpleAuth)方法获取到proxyAndInfo的实例,在通过proxyInfo的getproxy()方法获取到代理
对象赋给DFSClient的namenode成员变量,这样最终抽象类fs的实现DFS对象就拿到了namenode的代理(
遵循DFSClient Protocol),就可以调用远程namenode的方法了。
简单点说,就是在抽象类FileSystem中,通过反射获取到一个空对象DFS,在DFS中进行初始化,初始化的时候,重点考虑成员变量DFSClient的初始化,因其包含namenode成员变量,namenode成员变量就是远程namenode的代理。大致关系就是DFS->DFSClient->namenode。
Hadoop中的RPC主要是用动态代理实现的,根据类名反射出不同的对象,代理服务端的对象,此时就可以通过客户端在调用远端的方法,适合实时场景,响应速度比较快,一般传递元数据的这些信息,Java中的远程过程调用是用回调实现的,会阻塞,二者的底层都是通过TCP通信的。client和namenode之间使用rpc通信,namenode和secondarynamenode,namenode和datanode之间通过http通信。rpc的本质是使用了动态代理(动态一词的意思是使用反射机制,可以根据运行时的需要动态的获取不同的对象),底层封装了TCP用来通信。
补充一些调试时候一些操作:
- ctrl+o to show the inherited members,看成员变量和方法
- ctrl+t to see the hierarchy,看继承关系
- 注意看当前线程的方法栈,如果不小心多执行的几步,可以relaunch
- 抓住关键的地方,然后不断进入关键方法,打上断点跟踪